by playing video games.
OpenCV Object Detection in Games
Thresholding with Match Template
Detect multiple objects with OpenCV's match template function by using thresholding. In this tutorial, we dig into the details of how this works.
Links
GitHub repo: https://github.com/learncodebygaming/opencv_tutorials
OpenCV documentation: https://docs.opencv.org/4.2.0/
Official template matching tutorial: https://docs.opencv.org/4.2.0/d4/dc6/tutorial_py_template_matching.html
With thresholding, we can detect multiple objects using OpenCV's matchTemplate() function. They discuss briefly how to do this in the offical tutorial, but here I will cover it more in-depth.
Previously we used minMaxLoc() to get the best matching position for our needle image, but matchTemplate() actually returns a result matrix for all the positions it searched. It will look something like this:
[[ 0.65352035 0.59117913 0.5388891 0.48030487 0.41769522 0.42129537
0.47599143 0.38939482 0.2587495 -0.04214273 -0.30790046 -0.43191993
-0.53736794 -0.60625774 -0.6988619 -0.62993205 -0.60672116 -0.55576223
-0.49744758 -0.36477107 -0.18932077]
[ 0.84720045 0.8510587 0.82278675 0.7883967 0.8020412 0.73800206
0.58679795 0.48460892 0.19925155 -0.1656526 -0.40601757 -0.4887011
-0.51814693 -0.60923386 -0.6031463 -0.5300339 -0.5192606 -0.43797344
-0.34904873 -0.16709064 -0.07781255]
[ 0.7739218 0.76594543 0.7318738 0.69118077 0.7074286 0.5731589
0.45565775 0.34264973 -0.08615142 -0.28830773 -0.39431968 -0.41419375
-0.4670139 -0.4620724 -0.45220464 -0.41317672 -0.36051676 -0.24066429
-0.12146053 -0.03559997 0.05734708]
[ 0.7288387 0.7294983 0.6951163 0.69416976 0.53167534 0.4168399
0.30796996 0.19650966 -0.28582752 -0.34409058 -0.34616104 -0.3502209
-0.3488011 -0.32965192 -0.26975876 -0.19564907 -0.08763271 0.06590758
0.08027779 0.11524504 0.21640316]
[ 0.7112726 0.70503986 0.72786546 0.5745767 0.42078313 0.3032012
0.18246125 -0.01755125 -0.2942256 -0.25341988 -0.22987413 -0.11638643
-0.08742431 -0.02928047 0.10098883 0.20831059 0.33464068 0.33174
0.3632756 0.39676657 0.46134594]
[ 0.72698903 0.8025729 0.6059971 0.4845169 0.3318361 0.19896622
0.03443658 -0.2427643 -0.12897836 -0.18535984 0.05754557 0.235435
0.3400994 0.5078804 0.7006544 0.99667037 0.83895224 0.7191617
0.61449623 0.5671207 0.4410959 ]
[ 0.55424434 0.42289352 0.2986906 0.12559295 0.0751683 0.05018674
-0.10898264 -0.1606983 -0.06282645 0.07020158 0.2161499 0.34661284
0.43121335 0.53459704 0.7313065 0.7736217 0.76979077 0.75769085
0.6884893 0.55782086 0.47220033]
[ 0.11812816 0.45290726 0.31783807 0.13065974 0.00957353 -0.02769285
-0.10123918 -0.18649247 -0.05847391 0.15774377 0.27194703 0.37016967
0.4951306 0.6012426 0.68482983 0.71459883 0.71048045 0.73024815
0.5521021 0.44469982 0.382732 ]
[-0.03022894 0.13228303 0.16980162 -0.01873123 -0.12737927 -0.18445356
-0.21833827 -0.22478269 -0.09423549 0.15220605 0.30560225 0.39657825
0.5108289 0.5940894 0.68015385 0.6858562 0.74259096 0.5765755
0.4432066 0.32567564 0.21721628]
[-0.17221913 -0.328728 -0.30108014 -0.19070971 -0.2274392 -0.24711198
-0.20940922 -0.21954788 -0.19677465 0.10834529 0.29396334 0.4566228
0.44200948 0.5101394 0.57557803 0.6343124 0.4966526 0.37464127
0.26217458 0.13721119 0.0068255 ]]
Each value in this matrix represents the confidence score for how closely the needle image matches the haystack image at a given position. The index of the outer dimension represents the Y position, and the index of the inner list represent the X position. For example, the confidence value 0.58679795 in the data above corresponds to Y = 1 and X = 6. When we overlay the needle image on the haystack image, such that the upper left corner of the needle is placed at pixel position (6, 1), it's match score is 0.58679795.
Note that the resulting matrix size is (haystack_w − needle_w + 1) * (haystack_h − needle_h + 1). This is because there are no meaningful match results when the needle image is partially overhanging the haystack image.
The idea with thresholding is, we want to get the coordinates of all the places where the match confidence score is above some threshold number that we set.
To do that, the documentation suggests we should use the np.where() function. This will give us all the locations above that threshold.
threshold = 0.85
locations = np.where(result >= threshold)
print(locations)
# the np.where() return value will look like this:
# (array([1, 5], dtype=int32), array([1, 15], dtype=int32))
In the result, the first array contains the Y positions, and the second contains the X positions. So in the above example we found two matches above the threshold we set, at positions (1, 1) and (15, 5).
So we have the data we need know, but the format returned by np.where() isn't very convenient to work with. So lets convert it to a list of (X, Y) tuples.
locations = list(zip(*locations[::-1]))
print(locations)
# locations will now look like this:
# [(1, 1), (15, 5)]
In this line of code, [::-1] reverses a numpy array, so that we get the X values to come before the Y. Then the star * unpacks a list, so that we now have two one-dimensional arrays instead of one two-dimensional array. We then use zip() to merge those two lists into a bunch of new lists, each comprised of the elements from the input lists that share the same index. And because zip() actually returns a generator instead of a rendered list, we wrap it all in list() to get the final result we're looking for.
Here's a simplified example of how this line works:
res = [[10, 20, 30], [7, 8, 9]]
print(res[::-1])
# [[7, 8, 9], [10, 20, 30]]
print(*res[::-1])
# [7, 8, 9] [10, 20, 30]
print(zip(*res[::-1]))
# this is the same as calling zip([7, 8, 9], [10, 20, 30])
# prints a generator object that evaluates to: [(7, 10), (8, 20), (9, 30)]
print(list(zip(*res[::-1])))
# [(7, 10), (8, 20), (9, 30)]
So that's how we've converted the Y and X arrays returned by np.where() into a list of (X, Y) tuples.
Now that we have a list of matching locations, let's draw rectangles around all of those locations. We'll adapt our code from part 1 to do this, and simply loop over all the locations.
if locations:
print('Found needle.')
needle_w = needle_img.shape[1]
needle_h = needle_img.shape[0]
line_color = (0, 255, 0)
line_type = cv.LINE_4
# Loop over all the locations and draw their rectangle
for loc in locations:
# Determine the box positions
top_left = loc
bottom_right = (top_left[0] + needle_w, top_left[1] + needle_h)
# Draw the box
cv.rectangle(haystack_img, top_left, bottom_right, line_color, line_type)
cv.imshow('Matches', haystack_img)
cv.waitKey()
#cv.imwrite('result.jpg', haystack_img)
else:
print('Needle not found.')
You will get an image that looks like this:
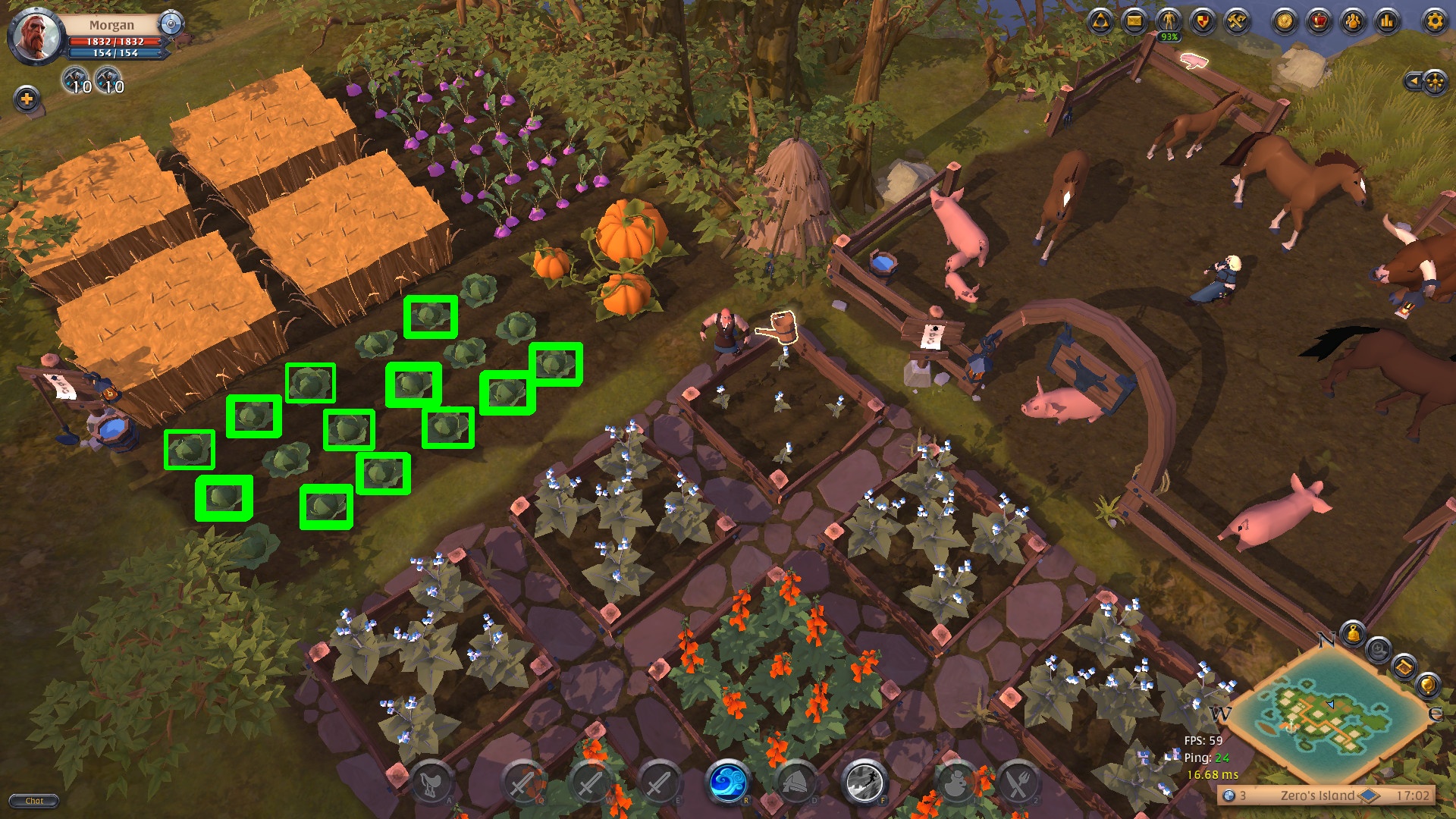
Keep adjusting your threshold, and your comparison method, until you get as many correct matches as possible without any false positives. In this case, I achieved the best result by using cv.TM_SQDIFF_NORMED and setting a threshold of values below 0.17 (remember TM_SQDIFF_NORMED uses inverted results).
You'll no doubt notice that you are getting many more location results than the number of rectangles you're seeing on the result image. You'll also notice that some of the rectangles are much thicker than others. This indicates that you're getting many match results that are very close to one another, and your rectangles are overlapping each other.
Visually this may not be too problematic, but if you're trying to count up the number of some item in an image, or if you're searching for screen locations to click on, then you'll need some way to clean this up. And that's what we'll be covering in part 3 of this tutorial: how to group those overlapping rectangles into single detection results.

Grouping Rectangles into Click Points

Fast Window Capture

Real-time Object Detection
 My name is Ben and I help people learn how to code by gaming.
I believe in the power of project-based learning to foster a deep understanding and joy in the craft of
software development.
On this site I share programming tutorials, coding-game reviews, and project ideas for you to explore.
My name is Ben and I help people learn how to code by gaming.
I believe in the power of project-based learning to foster a deep understanding and joy in the craft of
software development.
On this site I share programming tutorials, coding-game reviews, and project ideas for you to explore.